




Building an LLM or AI infrastructure in Rust can offer several benefits despite Python’s dominance in the AI space.
Performance: Rust is known for its high performance and low-level control, which can be crucial for building large-scale AI systems. Language models, especially deep learning models, can be computationally intensive, and Rust’s performance can lead to significant speed improvements compared to Python, making it more suitable for handling computationally expensive tasks efficiently.
Memory Safety: Rust’s strict compiler rules and ownership model ensure memory safety, preventing common bugs like null pointer dereferences and data races. This can make Rust-based AI systems more reliable and less prone to crashes, which is particularly important for long-running language models or critical AI applications.
Concurrency: Rust’s built-in support for concurrency and lightweight threads can lead to efficient utilization of multicore processors. This can be valuable when implementing parallel processing for training large language models or handling multiple inference requests simultaneously.
Yes, it is worth to remember that Python’s extensive ecosystem, well-established libraries (e.g., TensorFlow, PyTorch), and ease of use have made it the go-to choice for many AI projects. But if you have a sense of exploration, and pinned out your specific requirements and Rust is there at the top, this might be a relevant read for you.
Let’s try to answer the question: does Rust have a go-to all-inclusive library like Python has langchain for working with LLMs?
Chain library building blocks
If we zoom out for a minute, and ignore high-level workflows such as agents, toolkits, and baked use cases, we’ll be looking at the common infrastructure beneath all of those which allow for these high-level constructs to exist:
LLM — loading, calling LLMs and supporting different models, which need:
Embedding & Tokenization — turning text into embeddings, where text is loaded with:
Loaders — turning various document formats into LLM digestible, flat text, which needs to be post-processed by:
Splitters — to create legible, useful chunks of the original text, to work with LLM token limits and be stored in:
Vector databases — which are used to formulate prompts that are sent to LLMs, and also for powering:
Memory — which is done to support context and sessions with LLMs. But also, we have infrastructure for:
Templates — that structure a request from an LLM, which may contain a call for:
Tools — which are a collection of real-world tools such as a calculator or a browser for the LLM to automate by reading a structured prompt
So how does all of that look like currently in Rust?
Infrastructure and building blocks
LLM & Transformers
llm
https://github.com/rustformers/llm
llm is an ecosystem of Rust libraries for working with large language models - it's built on top of the fast, efficient GGML library for machine learning. It is a solid, expansive and stable library for working with models, to the point that this is the one library to always pick, and it’s a good thing that there aren’t many alternatives.
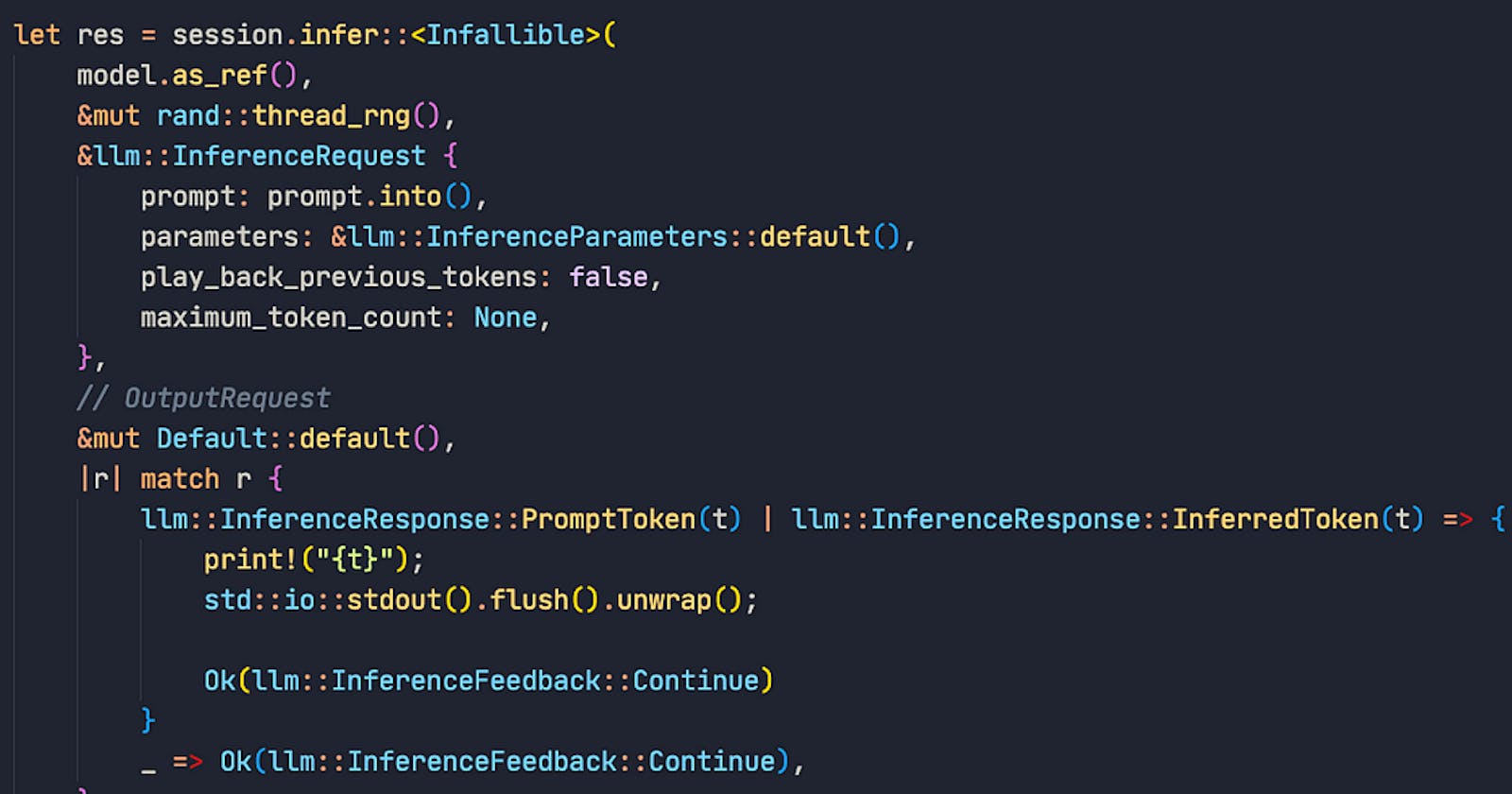
Here’s how to run inference using just the llm crate:
let model = llm::load_dynamic(
Some(model_architecture),
&model_path,
tokenizer_source,
Default::default(),
llm::load_progress_callback_stdout,
)
.unwrap_or_else(|err| {
panic!("Failed to load {model_architecture} model from {model_path:?}: {err}")
});
let mut session = model.start_session(Default::default());
let res = session.infer::<Infallible>(
model.as_ref(),
&mut rand::thread_rng(),
&llm::InferenceRequest {
prompt: prompt.into(),
parameters: &llm::InferenceParameters::default(),
play_back_previous_tokens: false,
maximum_token_count: None,
},
// OutputRequest
&mut Default::default(),
|r| match r {
llm::InferenceResponse::PromptToken(t) | llm::InferenceResponse::InferredToken(t) => {
print!("{t}");
std::io::stdout().flush().unwrap();
Ok(llm::InferenceFeedback::Continue)
}
_ => Ok(llm::InferenceFeedback::Continue),
},
);
rust-bert
https://github.com/guillaume-be/rust-bert
Probably the most versatile and productive library out there for rust for using transformer models, inspired by huggingface’s transformers library. This is a one stop shop for local transformer models, for different tasks from translation to embeddings.
Lots of use cases and examples
Very wide, as is the original transformers library
You can get a lot done just using this library and you might not need anything else
In terms of use cases, here’s an example sentiment analysis:
let sentiment_classifier = SentimentModel::new(Default::default())?;
let input = [
"Probably my all-time favorite movie, a story of selflessness, sacrifice and dedication to a noble cause, but it's not preachy or boring.",
"This film tried to be too many things all at once: stinging political satire, Hollywood blockbuster, sappy romantic comedy, family values promo...",
"If you like original gut wrenching laughter you will like this movie. If you are young or old then you will love this movie, hell even my mom liked it.",
];
let output = sentiment_classifier.predict(&input);
And embeddings:
let model = SentenceEmbeddingsBuilder::remote(
SentenceEmbeddingsModelType::AllMiniLmL12V2
).create_model()?;
let sentences = [
"this is an example sentence",
"each sentence is converted"
];
let output = model.encode(&sentences)?;
And plenty more use cases.
Embeddings & Tokenization
You can do embeddings with:
rust-bert
llm
tiktoken
https://github.com/zurawiki/tiktoken-rs
This library is built on top of the OpenAI Rust tiktoken library and extends it a bit. It should be a good one-stop-shop for your tokenization needs.
use tiktoken_rs::p50k_base;
let bpe = p50k_base().unwrap();
let tokens = bpe.encode_with_special_tokens(
"This is a sentence with spaces"
);
println!("Token count: {}", tokens.len());
Loaders
At the moment of writing, there is no unified loader like unstructured, that can load and convert documents without caring so much for implementation of the specific provider. Some of these may need some elbow grease to get content into a flat, LLM-document-like format (plain text, pages), for example looping over and extracting worksheet from Excel files.
However, here’s a sensible mapping from file format to an appropriate Rust library:
email: eml, msg https://crates.io/crates/eml-parser
epub pandoc
images (ocr) https://github.com/antimatter15/tesseract-rs
org mode (.org) https://github.com/hydrobeam/org-rust
open office https://lib.rs/crates/spreadsheet-ods, pandoc
txt (no need)
rtf pandoc
Splitters
https://github.com/benbrandt/text-splitter
The only library that is practical enough for splitting. Seems to be taking a “split properly” approach where you don’t need to choose if to split by newlines, characters, recursively or tokens. It will descend and use an appropriate method to maximize chunk sizes.
Prompts
At the moment of writing, there’s no general consensus, and no library that unifies the template concept like langchain has. However, taking a templating library and building on top of it is a great way to implement prompts.
Rust has a few fantastic templating libraries, which suit templating:
Handlebars — for standard, familiar, minimal logic templates
Tera — for those familiar with jinja2
Liquid — for those familiar with liquid
Most times, handlebars is the best bet that’ll be familiar to a general audience.
Vector Databases
At this point there’s no unified interface for vector databases, that provide a general wrapper around many different providers. If you survey a few open source projects around LLMs, you’ll find re-implementations of the same interfaces over and over which is a pitty, and — still, no one library that provides a generic interface.
Given such a simplistic interface, there seem to be a good ROI by building such a library, it should basically be:
add_documents
similarity_search
FYI — it just so happens that there are many individual vector databases implemented in Rust, both commercial and open source. Qdrant is probably the most popular open source one.
Memory
There are a few projects implementing memory, or history. Most of them implement a service which stores, indexes, and searches history for you, and they can also be used as reference for how to do your workflow in Rust dealing with AI.
Some interesting ones are:
memex — part of spyglass, a good code read, and does document storage and semantic search for LLM projects.
indexify — long term LLM memory
motorhead — memory / information retrieval
Tools
As of this writing, there are no tool / plugin libraries that are dedicated to this purpose only. That is, libraries that provide a solid interface for:
Declaring a tool
Capabilities
Running a tool (safely or not)
Structuring a tool request and response
However, implementations of those, can be found in the few chain implementation that rust currently has, which are discussed below.
Chains
llmchain-rs
https://github.com/shafishlabs/llmchain-rs
A small-scope chain library. I’d say 30% of what langchain-py has.
Early times for this project
Good amount of examples
Databend focused, but generic interfaces
Good test coverage (it’s a challenge testing LLM infra in any case)
Let’s look at some of the abstractions:
Embedding
pub trait Embedding: Send + Sync {
async fn embed_query(&self, input: &str) -> Result<Vec<f32>>;
async fn embed_documents(&self, inputs: &Documents) -> Result<Vec<Vec<f32>>>;
}
LLM
pub trait LLM: Send + Sync {
async fn embedding(&self, inputs: Vec<String>) -> Result<EmbeddingResult>;
async fn generate(&self, input: &str) -> Result<GenerateResult>;
async fn chat(&self, _input: Vec<String>) -> Result<Vec<ChatResult>> {
unimplemented!("")
}
}
- Integrations currently are: OpenAI, Azure-OpenAI and Databend, so probably mixing data from Databend with AI was the trigger for all of this
Document
#[derive(Debug, Clone, Eq, PartialEq)]
pub struct Document {
pub path: String,
pub content: String,
pub content_md5: String,
}
impl Document {
pub fn create(path: &str, content: &str) -> Self {
Document {
path: path.to_string(),
content: content.to_string(),
content_md5: format!("{:x}", md5::compute(content)),
}
}
pub fn tokens(&self) -> usize {
chat_tokens(&self.content).unwrap().len()
}
pub fn size(&self) -> usize {
self.content.len()
}
}
#[derive(Debug)]
pub struct Documents {
documents: RwLock<Vec<Document>>,
}
Prompt
pub trait Prompt: Send + Sync {
fn template(&self) -> String;
fn variables(&self) -> Vec<String>;
fn format(&self, input_variables: HashMap<&str, &str>) -> Result<String>;
}
Simple text based replacement of variables only
Single level, no advanced dependent or partial prompts
Vector Store
#[async_trait::async_trait]
pub trait VectorStore: Send + Sync {
async fn init(&self) -> Result<()>;
async fn add_documents(&self, inputs: &Documents) -> Result<Vec<String>>;
async fn similarity_search(&self, query: &str, k: usize) -> Result<Vec<Document>>;
}
Support for databend as a provider only
Missing MMR for search (like in all interfaces I’ve seen so far)
Missing save/load abstraction (but does it even belong in a trait?)
Overall
Relatively solid codebase, and good abstractions
Splitters (no abstraction or strategy to choose from, but this is the case with all chain implementations in Rust I’ve seen so far)
Memory (just early times there it feels)
llm-chain
https://github.com/sobelio/llm-chain
A more popular chain library, split into Rust crates, good Rust idioms and structure. Not a full coverage of what langchain-py has. Maybe 30% and still early times here as with all other libraries.
Let’s look at the abstractions here:
Embedding
#[async_trait]
pub trait Embeddings {
type Error: Send + Debug + Error + EmbeddingsError;
async fn embed_texts(&self, texts: Vec<String>) -> Result<Vec<Vec<f32>>, Self::Error>;
async fn embed_query(&self, query: String) -> Result<Vec<f32>, Self::Error>;
}
VectorStore
#[async_trait]
pub trait VectorStore<E, M = EmptyMetadata>
where
E: Embeddings,
M: serde::Serialize + serde::de::DeserializeOwned,
{
type Error: Debug + Error + VectorStoreError;
async fn add_texts(&self, texts: Vec<String>) -> Result<Vec<String>, Self::Error>;
async fn add_documents(&self, documents: Vec<Document<M>>) -> Result<Vec<String>, Self::Error>;
async fn similarity_search(
&self,
query: String,
limit: u32,
) -> Result<Vec<Document<M>>, Self::Error>;
}
Splitters
Looks like a splitter is a Tokenizer
pub trait Tokenizer {
fn tokenize_str(&self, doc: &str) -> Result<TokenCollection, TokenizerError>;
fn to_string(&self, tokens: TokenCollection) -> Result<String, TokenizerError>;
fn split_text(
&self,
doc: &str,
max_tokens_per_chunk: usize,
chunk_overlap: usize,
) -> Result<Vec<String>, TokenizerError>;
}
Prompt
Prompt is a construct which allows operating with an abstraction of Chat or Text messages. Templating is powerful and based on tera.
Document
#[derive(Debug)]
pub struct Document<M = EmptyMetadata>
where
M: serde::Serialize + serde::de::DeserializeOwned,
{
pub page_content: String,
pub metadata: Option<M>,
}
More similar than different in comparison to the langchain-py Document.
DocumentStore (Loader?)
#[async_trait]
pub trait DocumentStore<T, M>
where
T: Send + Sync,
M: Serialize + DeserializeOwned + Send + Sync,
{
type Error: std::fmt::Debug + std::error::Error + DocumentStoreError;
async fn get(&self, id: &T) -> Result<Option<Document<M>>, Self::Error>;
async fn next_id(&self) -> Result<T, Self::Error>;
async fn insert(&mut self, documents: &HashMap<T, Document<M>>) -> Result<(), Self::Error>;
}
Overall
Good separation between features and crates
Feels rusty
Lacking on splitters, loaders
Lacking integrations generally, and especially vector stores
SmartGPT
https://github.com/Cormanz/smartgpt
This is not a library nor infrastructure, but the internals are built well, and can be a good use for a chain library. Let’s have a look at the abstractions:
LLM
pub trait LLMModel : Send + Sync {
async fn get_response(&self, messages: &[Message], max_tokens: Option<u16>, temperature: Option<f32>) -> Result<String, Box<dyn Error>>;
async fn get_base_embed(&self, text: &str) -> Result<Vec<f32>, Box<dyn Error>>;
fn get_token_count(&self, text: &[Message]) -> Result<usize, Box<dyn Error>>;
fn get_token_limit(&self) -> usize;
fn get_tokens_from_text(&self, text: &str) -> Result<Vec<String>, Box<dyn Error>>;
}
Some methods removed because were default implemented.
Message
#[derive(Clone, Debug)]
pub enum Message {
User(String),
Assistant(String),
System(String)
}
Modeling a message on a User-AI-System pattern
MemorySystem (History?)
pub trait MemorySystem : Send + Sync {
async fn store_memory(&mut self, llm: &LLM, memory: &str) -> Result<(), Box<dyn Error>>;
async fn get_memory_pool(&mut self, llm: &LLM, memory: &str, min_count: usize) -> Result<Vec<RelevantMemory>, Box<dyn Error>>;
async fn get_memories(
}
...
A good interface of memory
Command (Tool?)
pub trait CommandImpl : Send + Sync {
async fn invoke(&self, ctx: &mut CommandContext, args: ScriptValue) -> Result<CommandResult, Box<dyn Error>>;
fn box_clone(&self) -> Box<dyn CommandImpl>;
}
Overall
This project has a relatively rich tool collection and might be the best start for a generic library that implements tools
Codebase is very pragmatic, because almost everything is actually in use
Where functionality was not needed — it does not exist (naturally), and this is where the codebase lacks, in comparison to langchain: splitters, loaders, prompt templates, vector stores and a general sense of multiple providers
To use it as a general purpose langchain library would be awkward, unless you hit the use cases that this project solves already. Which I think will not be enough pretty quickly.
